网站建设转载(Chinaz.com)注:网站链接分析,源于对Web结构中超链接的多维分析,是网站优化运营中不可缺少问题诊断方法。百度站长平台也推出其官方的链接分析工具。那么,我们该如何利用好百度站长工具的链接分析功能,来定位网站可能存在的SEO问题呢?
以下为来自百度站长社区斑竹响1亮2的3名4字的分享:
有一次在社区里面看到有站长朋友提问,说百度站长工具的链接分析里,怎么出现了锚文本是@NULL@的数据,感到非常不明觉厉。
然后我就试着联系了一些平时经常打交道的站长朋友,问了下他们是否关注过百度站长工具中的链接分析,是否定期进行过统一分析,当出现大量死链数据时,是否对问题进行了定位……结果发现有很多站长朋友,在平时很少进行这样的分析工作,所以当出现问题的时候,就感到不明觉厉,不由得大骂度娘坑爹。
实际上,度娘到底坑不坑爹我是不知道啦,不过我想说度娘只是把问题反映出来,更多地还需要我们自己去定位问题并进行处理,才能确保网站不会因为该问题而受到较大程度的影响。
于是,我就有了制作本期专题的打算,专题地址:http://bbs.zhanzhang.baidu.com/thread-75492-1-1.html。
1、本文的主要内容有哪些呢?
(1)查找是否有黑链出现——从日志分析,百度蜘蛛抓取了网站的哪些预期外的页面,是否存在黑链。(这个可能要先卖个关子,因为这又是个大工程啦,本期专题会提到一些)
(2)百度站长工具外链分析——查看是否有垃圾外链、黑链等,以及链向的站内什么地方,如何处理。(本期里面也有所涉及)
(3)百度站长工具链接分析——三大死链(内链死链、链出死链、链入死链),批量下载数据,合并数据,excel操作,按逻辑分类,定位问题,处理问题。(定位和处理,材料不够,因为好多已经处理过了,没有材料了= =|||||)
(4)从分析这些数据,得到的与SEO效果相关的其他信息(垃圾搜索引擎、垃圾外链带来的无用抓取,浪费资源配额,如何拒绝。)
(5)如何自动化地使用shell脚本,定位到被百度蜘蛛抓取到的死链,并进行复查,然后将确定为死链的URL进行自动化提交。(本期专题内容太多,留作下期专题用)
(6)分析工具介绍(firefox设置,插件,excel,windows命令提示符批处理)
2、本文中主要使用到的工具
(只是结合例子中,如果有其他相似功能的工具,请结合自身习惯使用即可)
【浏览器】火狐(Firefox)浏览器,版本无所谓
【插件】:Launch Clipboard
功能:一键打开剪切板中存在的URL。(注意URL中只能有英文数字标点,如果有中文可能无法被识别)。快捷键:alt + shift +K(先复制好单个或者多个URL)
设置:打开选项设置,选择好下载文件自动保存的位置(我这里选择了桌面,你也可以单独创建一个文件夹,好对批量下载的文件进行归类)
【表格处理】:Microsoft Office 2013 Excel
【文本处理】:Notepad++
【批量处理】:Windows自带命令提示符
一、我们可以先看一下外链分析。
分析外链数据的主要目的是,找出垃圾外链,主动去封堵垃圾外链可能对网站造成的恶劣影响。最终目标:
1、找到垃圾外链的域名,进行防盗链处理(针对来源为垃圾域名的,直接返回404状态码);
2、处理站内可能存在问题的页面。
这里,我会重点讲解第一点;第二点比较简单,我会讲解得比较粗略。
1、定位出垃圾域名。
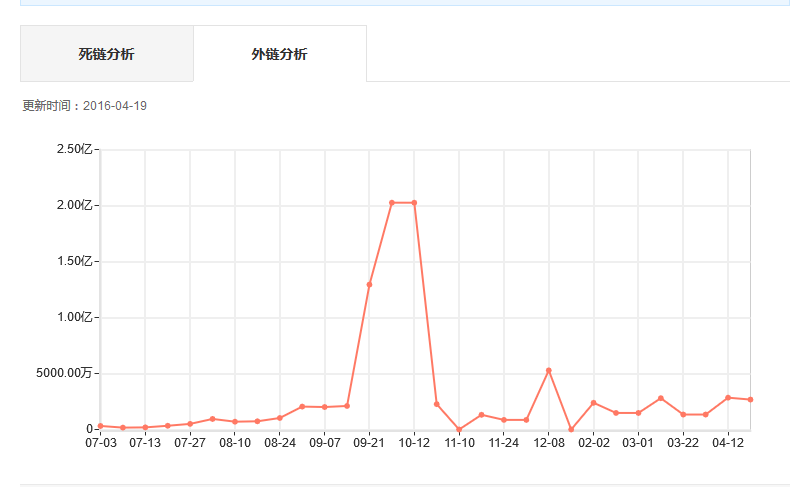
图注:可以看到这是一个明显不正常的趋势图
我们可以下载外链数据,来进行初步分析。

图注:下载得到的表格文件(csv逗号分隔符)
但是这样一份原始数据,是很难进行分析的。因此我们需要按照一定逻辑对其进行分析——就是按照【被链接的网页url】进行分类。
首先,我们可以快速浏览一下,进行直观判断,这些页面大部分是什么页面呢?
针对我们网站的情况来说,外链数据分为两类,正常外链与垃圾外链。
而垃圾外链又分为两种:站内搜索结果页面(垃圾搜索词)以及被黑客入侵植入的黑链(已经处理为死链)。
我们进行数据处理的目的有两个:识别出哪些是正常外链,哪些是垃圾外链,并根据垃圾外链的相关数据,进行一些处理,保护好网站;并且需要使被垃圾链接指向的页面,不被搜索引擎抓取(浪费抓取资源配额)以及被收录/索引(保证网站词库不受污染,不为网站带来形象与关键词方面的负面影响)。
第一步,筛选出网站的搜索结果页面
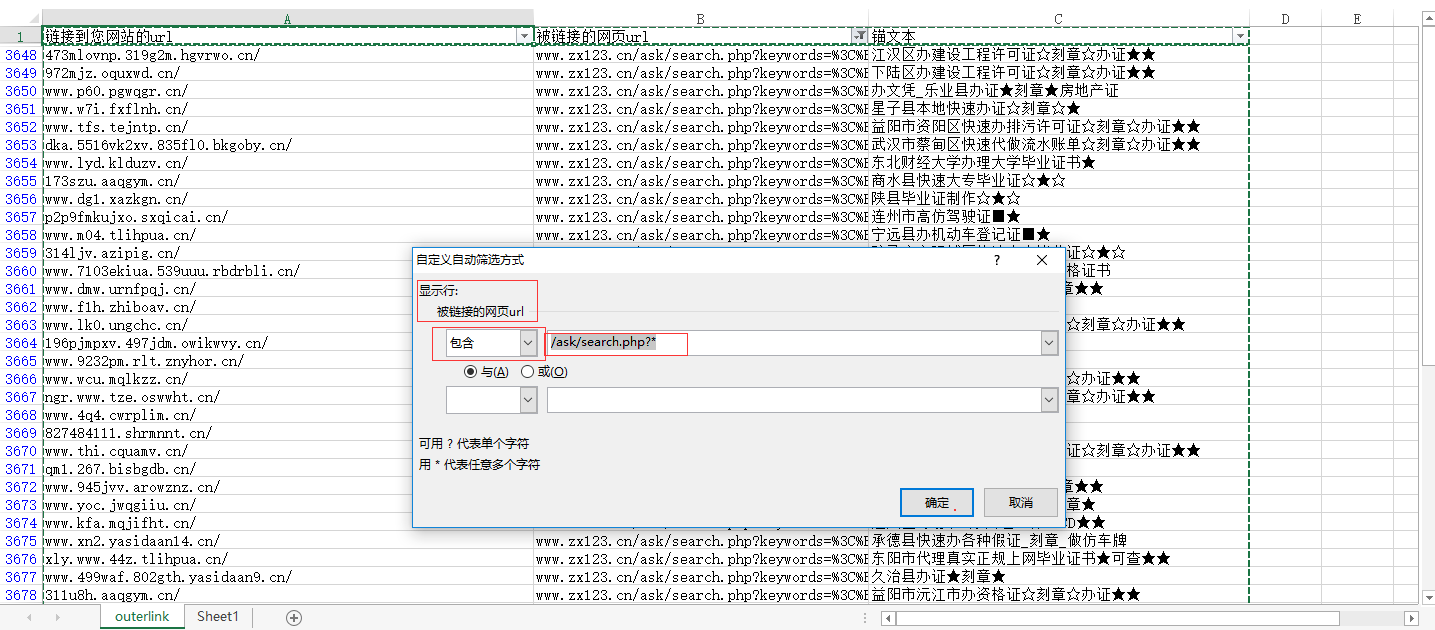

图注:筛选数据、复制到新的sheet中,删除原始sheet中的筛选数据,来分类数据
还有几类搜索链接格式,都以相同方式进行处理。
然后把原始sheet中剩下的数据进行去重(空白行),得到剩余的链接信息。

图注:对剩余数据进行简单的去重处理。
然后,我们需要对黑链进行筛选。黑链的数据,一般需要先从网站日志中分析得到(这样是最全面的,为了保证效率,会需要使用到shell脚本来自动运行,但是涉及篇幅过多,我将在以后的专题中进行讲解)。
当然也可以对表格中【被链接的网页url】这一列按照顺序排序后,挨着分析得到(自己去打开,同时黑客会使用一些特殊手段,妨碍我们去识别真正的会被搜索引擎识别到的垃圾内容,最常见的情况就是,使用js跳转。这样我们通过浏览器访问时,会看到完全不一样的内容,而搜索引擎抓取时,则下载到了垃圾内容。)
这时,我们需要使用一款firefox插件【No Script】,旨在屏蔽网站上的js,看到与搜索引擎类似的内容。

图注:屏蔽浏览器中java script的插件
另外还有一种不是很靠谱的甄选方法,在搜索引擎里面去搜:【site:域名 博彩】之类的关键词,把不符合网站预期的关键词拿去搜,就可以得到很多链接了。(这里需要使用一些方法,把链接全都批量导出,在今后的专题中,我会继续讲解的)
筛选过程我就只能省略啦,可以结合视频看一看。

图注:筛选出来的网站黑链
我们之所以要这么辛苦地找出垃圾外链,目的就是要把这些垃圾外链的域名记录下来,避免这些垃圾域名被黑客重复利用,拿去制作新的垃圾链接,从而在第一时间拒绝掉这些垃圾外链,使百度蜘蛛从垃圾外链访问我们网站上内容时,无法获取到任何信息(也就是返回404状态码,被识别成死链),久而久之,这些垃圾域名的权重就会越来越低(因为导出了死链,影响搜索引擎的正常抓取工作),这样我们不仅保护了自己,也惩罚了敌人。
具体方法是,把垃圾页面找出来——从搜索结果页面和黑链的两个sheet中,把外链页面整合到一起。如sheet3所示。

图注:合并垃圾外链页面
接下来的处理会使用到一款小工具,来快速获取这些链接的主域名。
https://www.benmi.com/getdomain.html

图注:将链接复制到左边红框里,点击本地提取,就会出现在右侧红框
如此一来,我们就得到了这些垃圾外链页面的主域名,我们只需要在我们服务器上配置一下防盗链,禁止refer(来源)为这些域名的访问(返回404http状态码)即可。
2、从站内对搜索结果页面进行处理(黑链处理我保留在下一次专题,因为要大量结合linux的shell脚本):
权重比较高的网站的站内搜索,一定要注意antispam(反垃圾)。如果不加以防范的话,一旦被黑客利用,那么可能会造成大量搜索页面被百度抓取,黑客利用高权重网站的资源,快速做好黄赌毒行业的关键词排名。但是这对于我们网站来说,则是噩梦般的打击。不作处理的话,可能会导致如下几方面的问题:浪费大量的蜘蛛抓取配额,去抓取垃圾页面;垃圾页面被搜索引擎收录,网站词库被黑客污染,使得网站的行业词和品牌词排名不理想;对网站形象造成损失……等。
在进行这类反垃圾策略的时候,我们需要关注四个方面:站内用户可以正常使用;不允许搜索引擎抓取这类页面;拒绝垃圾外链的访问;页面上不得出现垃圾关键词。
既然有了明确的目标,那么相应的应对方案也就出来了,那就是:
A 限制来源,拒绝掉所有非站内来源的搜索
B 页面上的TKD等关键位置,不对搜索词进行调用
C 指定敏感词库过滤规则,将敏感词全部替换为星号*(有一定技术开发要求)
D 在robots.txt声明,不允许抓取
E 在页面源代码head区间添加meta robots信息,声明该页面不允许建立索引(noindex)
进行以上处理,可以解决掉大部分站内搜索页面(不局限于该类页面,甚至其他的页面只要不希望搜索引擎抓取以及建立索引的话,都可以这样处理)容易出现的问题。
(编辑:小酷)

扫码添加客服微信
扫码关注公众号
酷网(大连)科技有限公司
致力于为客户品牌提供完善解决方案
统一服务电话:0411-62888851